GeForce RTX com IA Local: NVIDIA e OpenAI Liberam Modelos GPT para Rodar Offline
TECNOLOGIA
Redação
8/12/20252 min read


A NVIDIA firmou uma parceria com a OpenAI para permitir a execução de modelos GPT localmente em placas GeForce RTX, sem depender da nuvem. Essa novidade inaugura uma nova era de privacidade, desempenho real-time e autonomia de uso, ideal para criadores, desenvolvedores e gamers que buscam aproveitar o poder da IA avançada diretamente em seus PCs. As GPUs RTX oferecem borda computacional robusta, com núcleos Tensor que aceleram modelos de linguagem e visão por meio da arquitetura de inferência local
A inteligência artificial está mais próxima do usuário final. Agora, graças à colaboração entre NVIDIA e OpenAI, modelos GPT de última geração podem rodar diretamente nas placas GeForce RTX, proporcionando inferência local, sem a necessidade de conexão com servidores em nuvem. Essa abordagem melhora a privacidade, reduz a latência e democratiza o acesso à IA sofisticada.
Por que isso é importante?
Privacidade e segurança: Ao rodar localmente, seus dados permanecem apenas no seu PC, reduzindo riscos associados a transmissões via internet.
Desempenho otimizado: A GPU RTX tem núcleos Tensor capazes de processar modelos complexos com rapidez e eficiência — ideal para tasks em tempo real.
Acessibilidade e autonomia: Usuários sem excelente conectividade online podem usufruir do poder da IA sem depender da infraestrutura de nuvem.
Como funciona nas placas GeForce RTX?
As GPUs GeForce RTX já contam com hardware especializado – como os Tensor Cores – que permite aceleração de tarefas de inferência de modelos de linguagem como o GPT. Essa integração permite que aplicações inteligentes funcionem mesmo sem internet, com fluidez e respostas instantâneas.
Essa inovação abre um novo capítulo para a computação pessoal com IA, trazendo modelos avançados como GPT para a ponta. Executar inteligência artificial diretamente no seu PC com GeForce RTX representa uma revolução em eficiência, privacidade e conveniência.

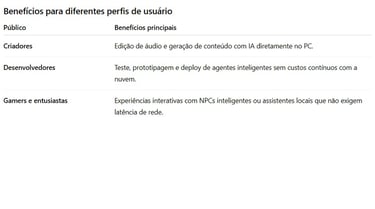
Imagem: Nvidia.com